




GPT-5.5 vs Claude 4.7 vs Gemini 3.1 vs Grok 4.20

OpenLM.ai continúa actualizando su punto de referencia Chatbot Arena+, lo que nos permite comprender Rendimiento en el mundo real de grandes modelos de lenguaje (LLM). En una batalla reñida, la brecha entre GPT-5.5 de OpenAI, Claude Opus 4.7 de Anthropic, Gemini 3.1 Pro de Google y Grok 4.20 de xAI es muy pequeña. La diferencia entre los cuatro líderes es la más cercana hasta el momento, pero ¿quién lidera la principal IA del mundo?
Clasificación mezclando datos y preferencias humanas
Antes de discutir este tema, debemos saber qué mide esta clasificación. El chatbot Arena+ incorpora el sistema Elo Arena basado en más de 6 millones de votos humanos Métricas estandarizadas como AAII v3, MMLU-Pro y ARC-AGI v2. Es decir, proporciona una instantánea completa del rendimiento de la precisión técnica, las capacidades de razonamiento y las evaluaciones subjetivas de los usuarios.
- AAII v3 (Evaluación Avanzada de Inteligencia Artificial v3): Puntos de referencia que analizan diferentes inferencias de modelos en 10 tareas técnicas complejas.
- MMLU-Pro (Comprensión masiva del lenguaje multitarea – Profesional): Versión avanzada que mide la comprensión del lenguaje en múltiples materias, todas a nivel universitario.
- ARC-AGI v2 (Desafíos de abstracción y razonamiento para AGI v2): Evaluación del razonamiento abstracto mediante acertijos visuales. Los humanos logran resultados cercanos al 100%, mientras que los modelos actuales de IA oscilan entre el 10% y el 20%.
Los 5 mejores programas LLM del mundo – mayo de 2026
| Ubicación | Modelo | Calificación general | codificación | imaginar | AII v3 | MMLU-Pro (%) | ARCO-AGI v2 |
|---|---|---|---|---|---|---|---|
| 1 | GPT-5.5-Alto | 1506 | Capítulo 1562 | 1312 | 76 | 89,6 | 85 |
| 2 | Claude Ops 4.7 Pensamientos | 1505 | Capítulo 1565 | 1310 | 76 | 90 | 75,8 |
| 3 | Géminis-3.1-Pro | 1505 | Capítulo 1531 | 1309 | 76 | 91 | 77.1 |
| 4 | Claude trabaja 4.7 | 1503 | Capítulo 1554 | 1300 | 73 | 89,9 | 65,5 |
| 5 | Claude Ops 4.6 Pensamientos | 1503 | Capítulo 1545 | 1304 | 73 | 89,7 | 69.2 |
Batalla de titanes: pequeñas diferencias, diferentes estrategias
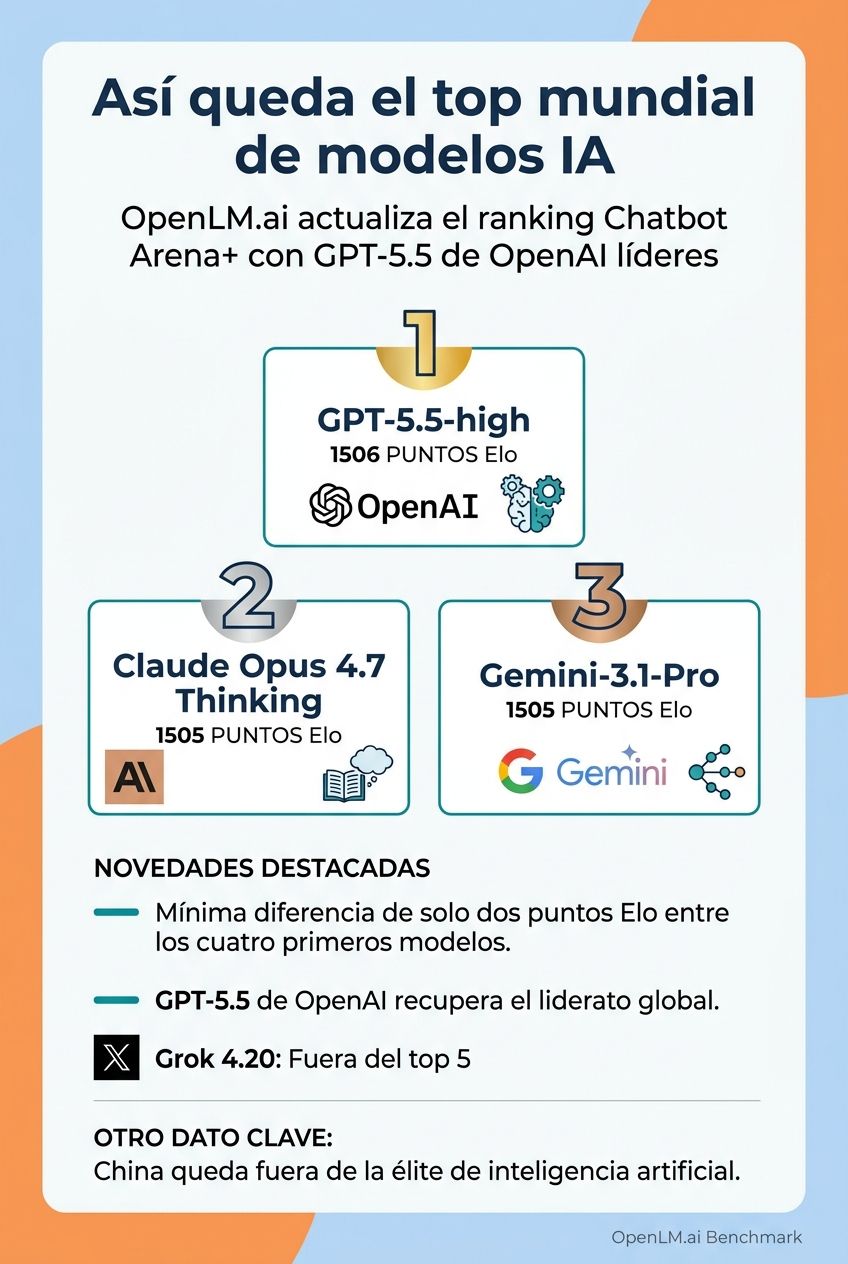
Lo que se puede ver a simple vista. Basado en datos de OpenLM.ai Ésta es la gran igualdad entre los grandes modelos lingüísticos. GPT-5.5-Alto Actualmente ocupa el primer lugar con una puntuación Elo de 1506, pero Claude Opus 4.7 Thinking y Gemini-3.1-Pro le siguen de cerca con 1505 puntos. Antes de esta actualización, el Gemini 3.1 Pro había estado liderando el grupo, pero las cosas han cambiado.
Para ChatGPT, se reanuda OpenAI GPT-5.5-high es un líder mundial. Además de su puntuación Elo de 1506, sobresale especialmente en codificación, con una puntuación de 1562 y 85 en ARC-AGI v2. Aunque no es una victoria abrumadora, sí muestra los esfuerzos de OpenAI por volver a lo más alto del ranking.
Claude Ops 4.7 Pensamientos Esta es probablemente una de las grandes sorpresas de la clasificación. Si bien no lideró por un solo punto, logró el mejor puntaje de codificación entre los cinco primeros, con 1565 puntos. Por su parte, Grok 4.20 avanza en entornos conversacionales. Personalmente, estoy totalmente de acuerdo con esta clasificación basada en mis hábitos, pero le doy un poco más de crédito a Elon Musk por su IA en la codificación.
La IA de China surge de la élite
Aunque nos centramos en los modelos más familiares, p. GPT-5.5 de OpenAI, Claude Opus 4.7 de Anthropic, Gemini 3.1 Pro de Google y Grok 4.20 de xAILa verdad es que las clasificaciones ocultan muchas cosas que requieren análisis. Por supuesto, muchos se sorprenderán de que la IA china más popular de los últimos meses no esté en lo más alto de la lista.
por un lado, ERNIE-5.1 de Baidu Es el modelo chino mejor clasificado con 1475 puntos Elo. Si miramos más abajo en la clasificación, tenemos GLM-5.1, DeepSeek-V4-Pro y Qwen3.5-Max, que están todos en territorio muy parejo pero ya van rezagados por OpenAI, Anthropic y Google.
Hay muchos problemas con estos modelos porque Restricciones de acceso a chips de alto rendimiento Debido a las regulaciones de exportación impuestas por Estados Unidos. Esto limita las capacidades de formación en comparación con los competidores occidentales.
Qué significa este resultado para la industria
La primera posición de ChatGPT 5.5 no es definitiva, Tampoco puedo dejar que la gente de OpenAI se duerma en los laureles.. La diferencia en puntos Elo entre los cuatro primeros es inferior a 2, lo que es una indicación interesante de la madurez del modelo lingüístico. Tampoco podemos dejar de prestar atención a la inteligencia artificial que llega desde China y nos sigue de cerca.
Actualmente, los cuatro principales gigantes mundiales de la IA han experimentado esto:
- inteligencia artificial abierta Recupere el liderazgo global con GPT-5.5-high.
- selección antrópica Clasificando tres modelos entre los 5 primeros, con Claude Opus 4.7 Thinking firmando para obtener la mejor puntuación de codificación.
- Google Aunque perdió la primera posición, Gemini-3.1-Pro sigue casi empatado con el líder y mantiene los mejores datos entre MMLU-Pro.
- xAI Salió del top 5 junto con Grok 4.20, aunque todavía está cerca de la cima.
Esta es una buena noticia para los usuarios.. Más y mejor competencia nos permite ir probando cada modelo hasta encontrar el que mejor se adapta a nuestras necesidades. Incluso podemos optar por tener múltiples tareas al mismo tiempo, dedicando cada una a un tipo de tarea.
¿Qué modelo de IA utilizar según la tarea?
| Modelo | fortaleza principal | puntos de referencia clave | Puntuación destacada | Muy adecuado para… |
|---|---|---|---|---|
| Géminis profesional | Análisis multimodal (texto + imagen) | MMMU | 79,6% | Analizar documentos a través de diagramas, revisión visual, investigación científica. |
| Tecnología general 5 | Programación de algoritmos | evaluación humana | 92,7% | Desarrollador, resolución de problemas de código, integración al ecosistema de Microsoft. |
| Claudio 4.5 | Verdadera seguridad y cifrado | Banco SWE | 72,5% | Proyectos empresariales, mantenimiento de código y entornos con altos requisitos de seguridad. |
| Gronk-4 | situación de diálogo | Preguntas y respuestas del diálogo | 84,3% | Atención al cliente avanzada, análisis de conversaciones largas, coherencia narrativa. |
¿Cuánto cuesta utilizar estos modelos?
Las versiones gratuitas de Gemini 3.1, GPT 5.5, Claude 4.7 y Grok 4 tienen disponibilidad limitada. También es posible pagar por funciones adicionales, que cuestan unos 20 euros al mes, según la plataforma. Gemini 3.1 Pro tiene un precio de 21,99 euros al mes, GPT 5.5 vía OpenAI cuesta 23 euros al mes, Claude 4.7 cuesta 17 dólares al mes y Grok 4 integrado en X Premium cuesta unos 16 euros.
en conclusión
Según los analistas de OpenLM.ai, “Se acabaron los tiempos del modelo dominante, la clave ahora es la adaptabilidad y la integración en el ecosistema de uso actual”. Esto significa que hay que buscar Otras formas de convencer a los usuarios Continuar tomando el pulso al mercado de la inteligencia artificial.
GPT-5.5 de OpenAI, Claude Opus 4.7 de Anthropic, Gemini 3.1 Pro de Google y Grok 4.20 de xAI ya no están separados por la potencia bruta, sino por diferencias sutiles en integración, API y filosofías de diseño. La próxima actualización de la clasificación está prevista para finales del verano de 2026, cuando una vez más podremos ver fielmente las nuevas versiones y modelos abiertos que están despegando.
Preguntas frecuentes sobre el ranking mundial de IA de 2026 Según los datos de Chatbot Arena+, Claude Opus 4.7 Thinking lidera la sección de codificación con 1565 puntos, ligeramente por encima de la puntuación más alta de GPT-5.5 de 1562 puntos.
A pesar de su popularidad, estos modelos están sujetos a restricciones estadounidenses sobre chips de alto rendimiento, lo que limita sus capacidades de entrenamiento en comparación con OpenAI o Anthropic.
GPT-5.5-high destaca en la prueba ARC-AGI v2, con una puntuación de 85, una de las puntuaciones más altas para un modelo comercial.
Los precios rondan los 20 euros: GPT-5.5 cuesta 23 euros/mes, Gemini 3.1 Pro cuesta 21,99 euros/mes, Claude 4.7 ronda los 17 USD, Grok 4 con X Premium ronda los 16 euros.
Gemini 3.1 Pro de Google mantiene los mejores resultados en la prueba comparativa MMLU-Pro, que mide con precisión la comprensión del lenguaje en múltiples disciplinas profesionales.
¿Cuál es la IA más poderosa programada actualmente?
¿Por qué las IA chinas como ERNIE o Qwen no están entre las cinco primeras?
¿Qué modelo es mejor para resolver acertijos visuales y razonamiento abstracto?
¿Cuánto cuesta una suscripción mensual para el modelo principal?
¿Qué IA puede comprender mejor el lenguaje de nivel universitario?
Puedes consultar la fuente de este artículo aquí